
The traditional urgent-important matrix fails entrepreneurs managing 50+ competing
priorities across multiple projects simultaneously. Modern AI-powered prioritization
frameworks leverage multi-criteria scoring that evaluates tasks against business value,
feasibility, and velocity, then recalibrates continuously as contexts shift. RICE methodology calculates reach times impact times confidence divided by effort while MoSCoW categorizes must-should-could-won’t systematically; implementing these intelligent AI prioritization systems transforms paralyzing overwhelm into objective clarity about where your attention creates maximum leverage today.
AI-powered task prioritization: Beyond the Eisenhower Matrix.
The traditional urgent-important matrix fails entrepreneurs managing 50+ competing priorities across multiple projects simultaneously. You stare at your endless task list each morning and the familiar anxiety creeps in about where to start.
The old framework served well in simpler times, but modern business complexity demands more sophisticated approaches. Your decisions involve multiple dimensions beyond simple urgency and importance. Business value, technical feasibility, velocity to results, resource constraints, and strategic alignment all influence what deserves attention today.
Modern AI-powered prioritization frameworks leverage multi-criteria scoring that evaluates tasks against these variables, then recalibrates continuously as contexts shift. These AI methods transform paralyzing overwhelm into objective clarity about where your attention creates maximum leverage right now.
Why the Eisenhower Matrix falls short.
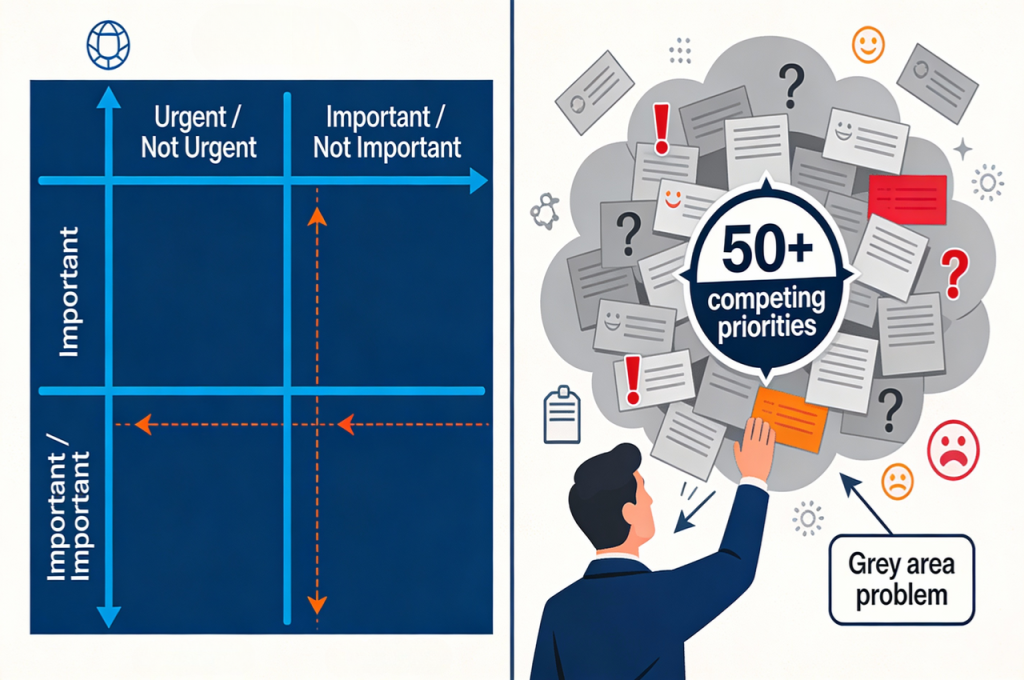
President Eisenhower’s two-by-two grid dividing tasks into urgent-important combinations revolutionized productivity thinking decades ago. The concept remains sound, but implementation at scale becomes problematic for several reasons.
The binary classification forces artificial choices. Many tasks exist in gray areas where urgency and importance both register moderate levels. How do you categorize medium-urgent, medium-important activities relative to each other?
Cognitive biases corrupt manual classification consistently. Urgent items scream louder than important ones even when you consciously know better. Unpleasant but valuable tasks get unconsciously downgraded.
The matrix assumes static conditions, but entrepreneurial contexts change constantly. A task classified yesterday may shift categories today based on new information, client feedback, or competitive moves.
Finally, the system ignores effort required and resource availability. Two equally important urgent tasks may differ dramatically in execution difficulty.
RICE: AI-Enhanced Reach × Impact × Confidence ÷ Effort.
The RICE methodology developed by Intercom provides elegant solution for product and project prioritization. The AI-enhanced framework evaluates four dimensions that capture nuanced trade-offs better than binary urgent-important classification.
Reach measures how many people or customers this task will affect. Launching a feature used by 80% of your customer base scores higher than one serving a small niche segment.
Impact assesses the intensity of effect on those reached. A massive improvement to core functionality rates higher than a minor convenience enhancement. Impact typically uses a simple scale like 3 for massive,2 for high, 1 for medium, and 0.5 for low effect.
Confidence reflects your certainty about the reach and impact estimates. Thoroughly researched initiatives with customer validation earn high confidence scores while speculative ideas rate lower.
Effort estimates the total person-months required to complete the work. A task needing
6 person-months of development scores 6 regardless of how many people work on it.
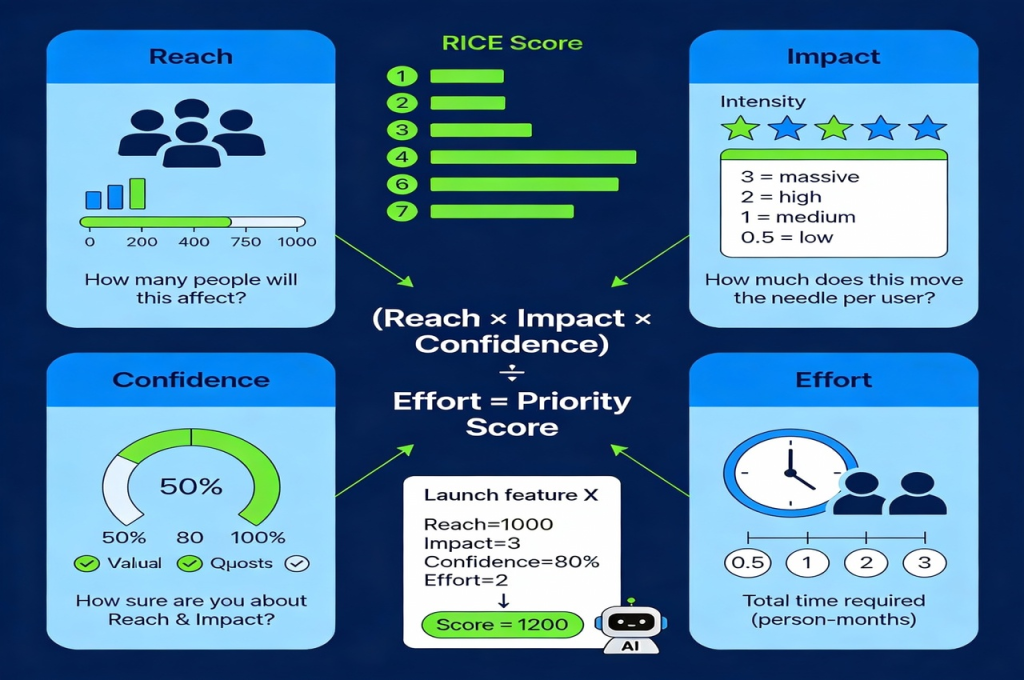
The RICE score multiplies reach times impact times confidence, then divides by effort.
Higher scores indicate better returns on invested resources.
AI-powered tools like Monday and ClickUp automate RICE scoring once you define evaluation criteria. New tasks receive AI-calculated scores automatically based on attributes you assign.
MoSCoW: AI-Powered Must-Should-Could-Won’t Framework
The MoSCoW method created for software development applies beautifully to
entrepreneurial resource allocation. The AI-enhanced framework categorizes every item into four explicit buckets that clarify trade-offs.
Must-have items represent non-negotiables without which the project fails entirely. These are true requirements, not nice-to-haves disguised as necessities. For a product launch, this might include core functionality, payment processing, and basic user documentation.
Should-have activities bring significant value and rank just below must-haves. They’re important but the project could ship without them if time constraints demand tough choices.
Could-have tasks improve the experience but remain clearly optional. They’re implemented only if time and budget permit after completing must and should categories.
Won’t-have this time items get explicitly documented as out of scope for current phase.
This public acknowledgment prevents them from sneaking back into discussions or creating scope creep.
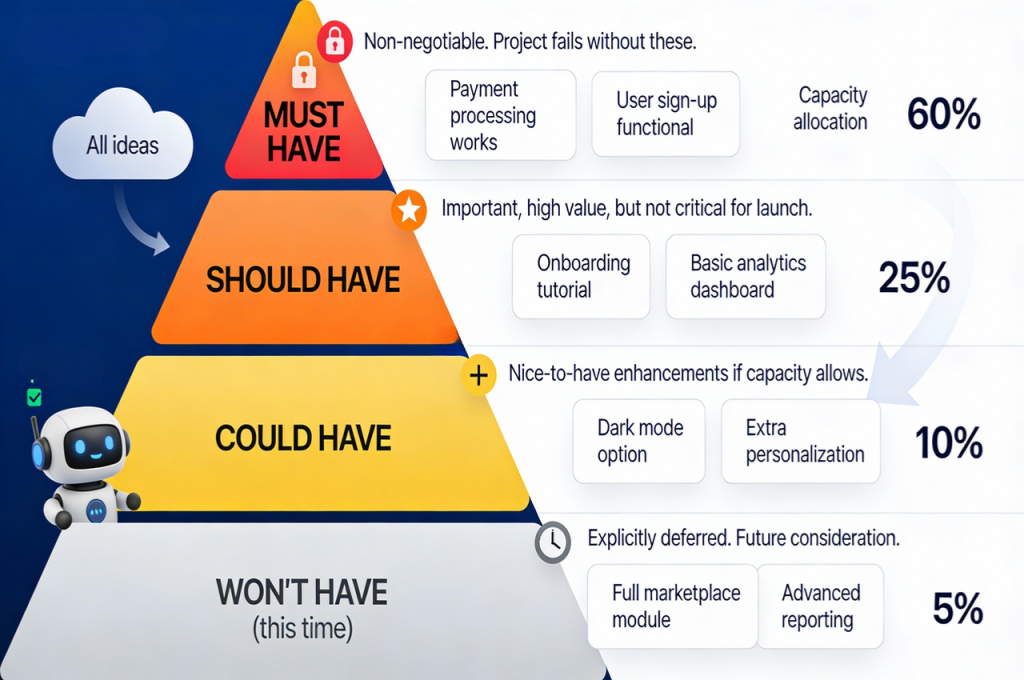
The brilliance lies in forcing explicit classification rather than implicit assumptions. Team members can’t claim everything is critical when only one category accepts that designation.
AI-powered Asana enables MoSCoW implementation through custom fields that auto-sort and filter tasks. Your backlog organizes itself by priority category and you focus attention where it belongs.
Kano Model: AI analysis of satisfiers versus delighters.
The Kano Model distinguishes features and tasks based on their relationship to customer satisfaction. This AI-enhanced framework prevents wasting effort on improvements that
customers don’t value.
Basic expectations represent must-have capabilities customers assume exist. Their presence generates no excitement but their absence creates intense dissatisfaction. For email software, this includes sending, receiving, and searching messages.
Performance factors correlate linearly with satisfaction. More speed, capacity, or accuracy produces proportionally higher satisfaction. Customers compare vendors on these dimensions.
Excitement factors delight customers unexpectedly because they didn’t anticipate these capabilities. Their absence causes no dissatisfaction since customers never expected them, but their presence generates disproportionate enthusiasm.
Indifferent features neither help nor hurt regardless of implementation quality. Customers don’t care about these aspects and improving them wastes resources.
The Kano framework guides investment toward AI-powered excitement factors that
differentiate your offering rather than parity features that merely keep you competitive.
Value versus effort matrix: AI-Powered visual prioritization.
The value-effort matrix provides visual prioritization especially useful for cross-functional discussions. The two-axis grid plots every initiative by estimated business value and required effort, creating four AI analyzed quadrants.
Quick wins land in the high-value, low-effort quadrant and deserve immediate attention.
These opportunities generate disproportionate returns and build momentum through visible progress.
Major projects occupy the high-value, high-effort quadrant and require careful scheduling. These strategic initiatives justify significant resource investment but can’t all happen simultaneously.
Fill-ins appear in the low-value, low-effort quadrant and work well for spare capacity.
These minor improvements and small fixes make sense when team members have downtime.
Time wasters occupy the low-value, high-effort quadrant and deserve elimination or indefinite postponement. These activities consume resources without justifying the investment.
The visual representation facilitates alignment during team discussions. Disagreements about priority become concrete debates about value and effort estimates rather than abstract arguments.
ICE Score: AI-simplified Impact-Confidence-Ease.
The ICE framework simplifies RICE by removing the reach dimension and using inverted effort scale. This streamlined AI-powered approach works well for startups where every initiative potentially affects the entire customer base.
Impact measures the potential positive effect on key metrics like revenue, retention, or growth. Use a 1-10 scale where 10 represents massive impact and 1 indicates minimal effect.
Confidence reflects certainty about the impact estimate. How much validation, research,
or data supports your assumptions? Confidence also uses 1-10 where 10 means
certainty and 1 indicates pure speculation.
Ease inverts the effort concept by measuring how simple the task is to complete. A 10
means trivially easy while 1 represents extremely difficult.
The AI-calculated ICE score simply adds the three numbers together. Higher totals indicate better opportunities.
Many entrepreneurs prefer ICE for early-stage work when speed matters more than
precision. The simplicity enables rapid AI-powered scoring without analysis paralysis.
Connecting AI prioritization to your tools.
The real power emerges when your AI prioritization framework connects to operational systems that execute work. ClickUp and Monday both support custom fields that calculate scores automatically based on attributes you assign to tasks.
Define your chosen framework’s criteria as custom AI fields. For RICE, create reach, impact, confidence, and effort fields. Set up a formula field that computes the AI score automatically.
AI integration with external data sources enriches scoring accuracy. Connect your CRM to automatically populate reach based on account size. Link analytics to inform impact estimates with usage data.
Dynamic AI recalculation keeps priorities current as conditions evolve. A task’s score updates automatically when you modify any input variable.
Zapier and Make orchestrate these connections between systems without coding. Your AI prioritization framework becomes automated intelligence layer across your entire tool stack.
Learning from your AI-enhanced decisions
The most sophisticated AI prioritization involves retrospective analysis of past choices.
Which high-priority tasks actually delivered expected value? Where did your impact
estimates prove optimistic or pessimistic?
This AI-powered feedback loop refines your scoring over time. You discover that certain types of tasks consistently take longer than estimated and apply correction factors.
Quarterly AI-enhanced reviews of completed work against initial priorities reveal patterns.
Perhaps quick wins actually generated more cumulative value than major projects. Document your methodology and AI adjustment factors so the system improves systematically rather than relying on intuition alone. This institutional learning becomes competitive advantage as your AI prioritization accuracy increases year over year.
For comprehensive integration of these prioritization methods with automated scheduling and systematic time tracking, explore how AI transforms time management frameworks combine multiple optimization layers to generate compounding productivity gains.